全网最低价dy业务平台,你确定不来看看?
全网最低价dy业务平台在线:您的理想选择
一、什么是dy业务平台?
dy业务平台,即抖音业务平台,是依托于抖音这一热门短视频平台,为用户提供一站式商业解决方案的服务平台。在这个平台上,商家和个人可以轻松开展电商、广告、直播等业务,实现品牌推广和产品销售的双重目标。
随着抖音用户数量的激增,dy业务平台也逐渐成为了商家和品牌争相入驻的热门选择。它不仅为用户提供了一个展示产品的舞台,还提供了一个高效、便捷的营销工具。
二、全网最低价,dy业务平台如何做到的?
全网最低价,是dy业务平台的一大亮点。那么,它是如何实现这一优势的呢?
首先,dy业务平台通过与抖音平台深度合作,获得了一手的流量资源。这使得平台上的商家能够以更低的价格获取到更多的曝光机会,从而降低了营销成本。
其次,dy业务平台拥有一支专业的运营团队,他们通过对市场数据的深入分析,能够为商家提供精准的营销策略,帮助商家在竞争激烈的市场中脱颖而出。
此外,dy业务平台还通过优化供应链,降低产品成本,将节省下来的成本以更低的价格回馈给用户,实现了全网最低价的目标。
三、在线操作,dy业务平台为您提供便捷服务
dy业务平台提供在线操作服务,让商家和用户都能轻松上手。以下是一些平台提供的便捷服务:
1. 简单易用的后台管理系统:商家可以通过后台管理系统轻松管理店铺、商品、订单等,无需专业知识。
2. 专业的客服团队:遇到问题时,商家可以随时联系客服团队,获取帮助。
3. 丰富的营销工具:平台提供多种营销工具,如优惠券、限时抢购、直播带货等,帮助商家提高销售额。
4. 专业的培训课程:平台为商家提供各类培训课程,帮助商家提升运营能力。
综上所述,dy业务平台凭借其全网最低价、便捷的在线操作和专业的服务,成为了商家和用户的理想选择。
每经编辑|兰素英
4月24日, DeepSeek-V4预览版正式发布并同步开源,号称在Agent能力、世界知识与推理性能三大维度达到国内及开源领域领先水平。
DeepSeek-V4分为Pro与Flash两个版本,均支持百万(1M)token超长上下文。
两个版本均大幅降低了对计算和显存的需求,将每个标记的推理FLOP降低 73%,并将KV缓存内存占用降低90%。

4月24日,全球最大AI模型应用程序编程接口聚合平台OpenRouter的数据显示,V4-Flash的调用量达270亿Token,V4-Pro为47.9亿Token,但没有登上排行榜。
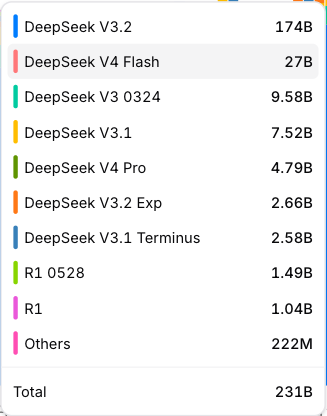
DeepSeek-V4发布后,主流评测平台进行了能力测试和排名。
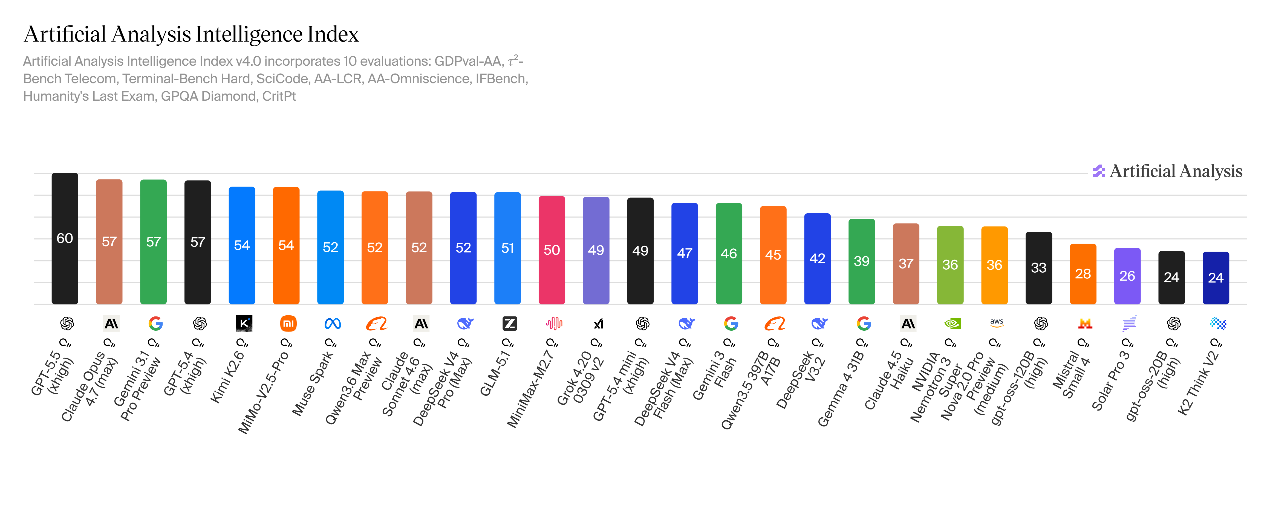
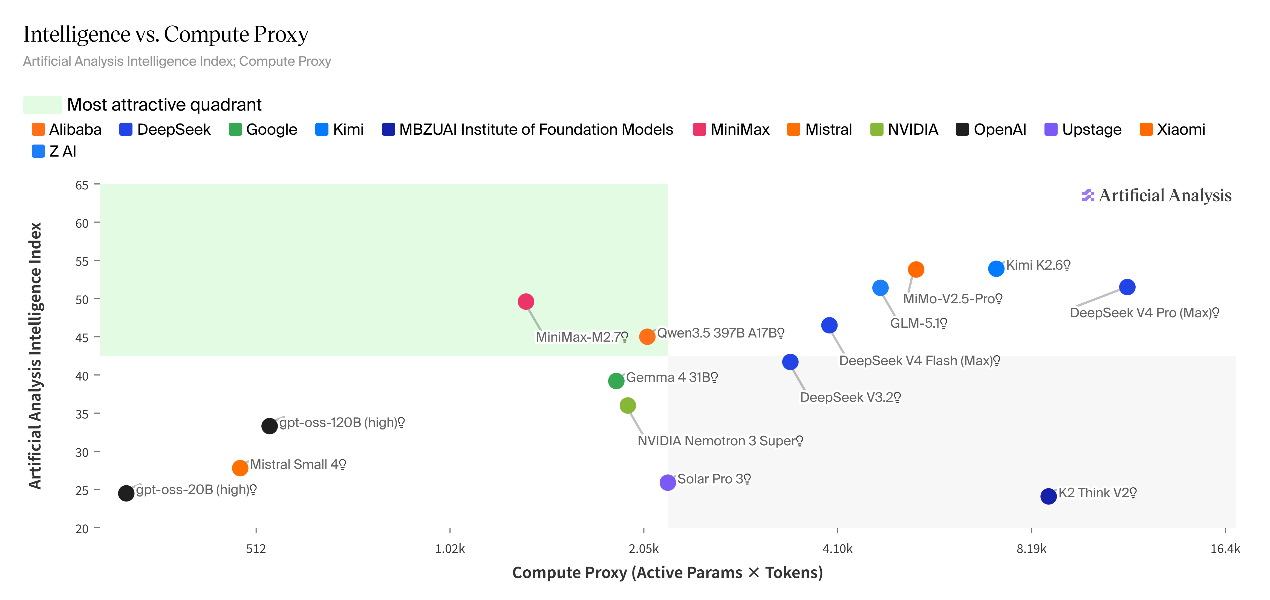
Artificial Analysis对DeepSeek-V4进行了推理能力专项测评。结果显示,V4-Pro在人工分析智能指数中斩获52分,相较V3.2版本的42分实现10分跃升,成为仅次于Kimi K2.6的全球第二大开源推理模型。
V4-Flash得分47分,性能弱于V4-Pro,但显著超越DeepSeek-V3.2,综合智能水平对标Claude Sonnet 4.6(全力版),介于顶尖闭源模型与主流中端模型之间。
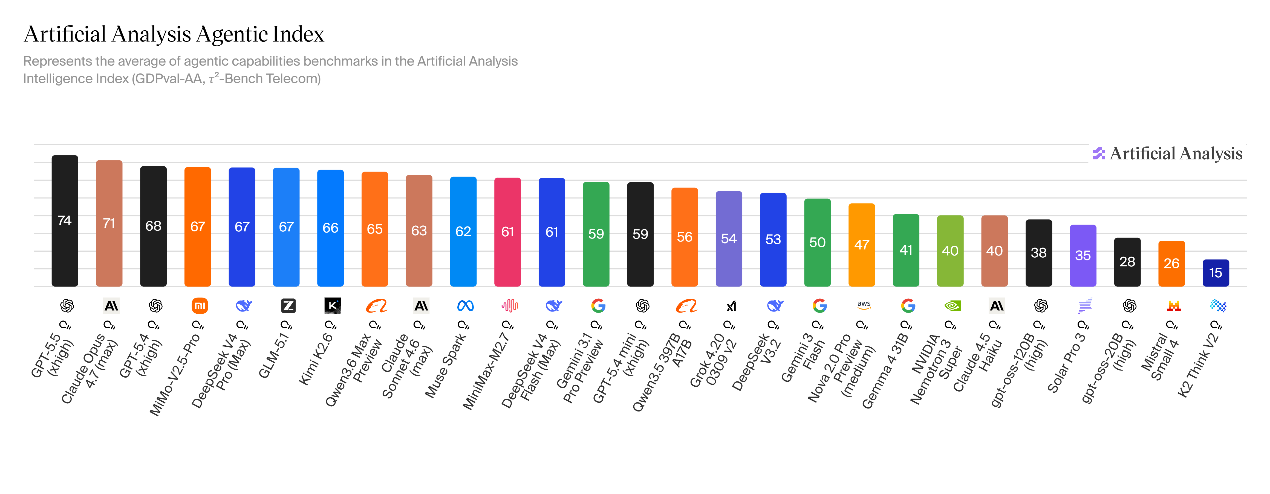
在智能体任务表现方面,V4-Pro在真实场景智能体工作任务中,性能位居所有开源权重模型首位,得分1554,超越Kimi K2.6(1484)、GLM-5.1(1535)、GLM-5(1402)以及MiniMax-M2.7(1514)。
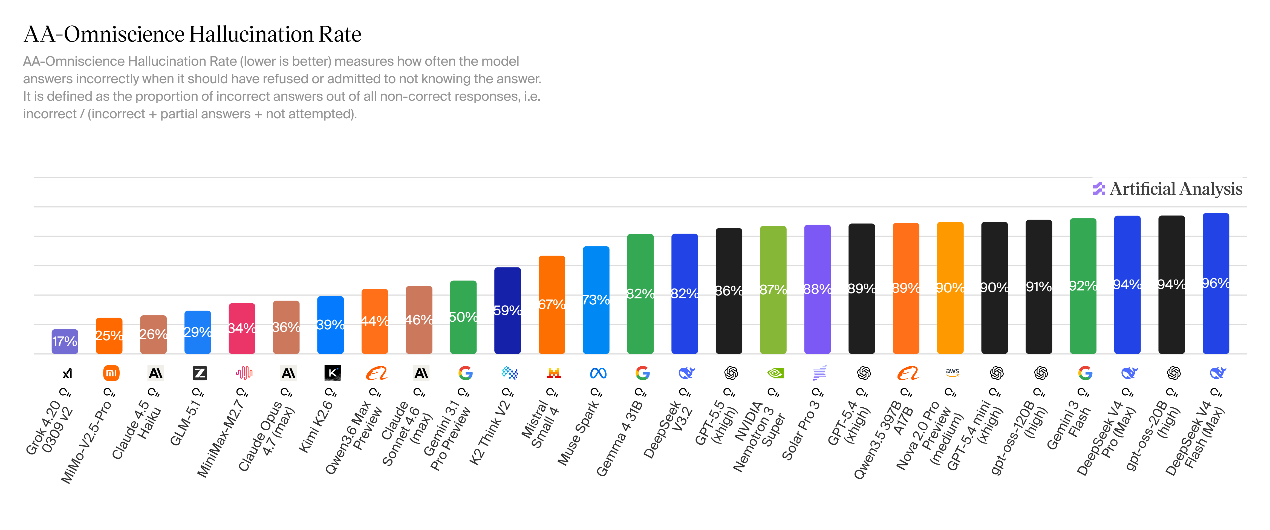
DeepSeek-V4知识储备升级,但幻觉发生率上升。V4-Pro在全知综合评测指标(AA-Omniscience)中得分为-10,较V3.2推理版提升11分,核心得益于知识回答准确率的显著优化。V4-Flash得分为-23,整体水平与V3.2基本持平。
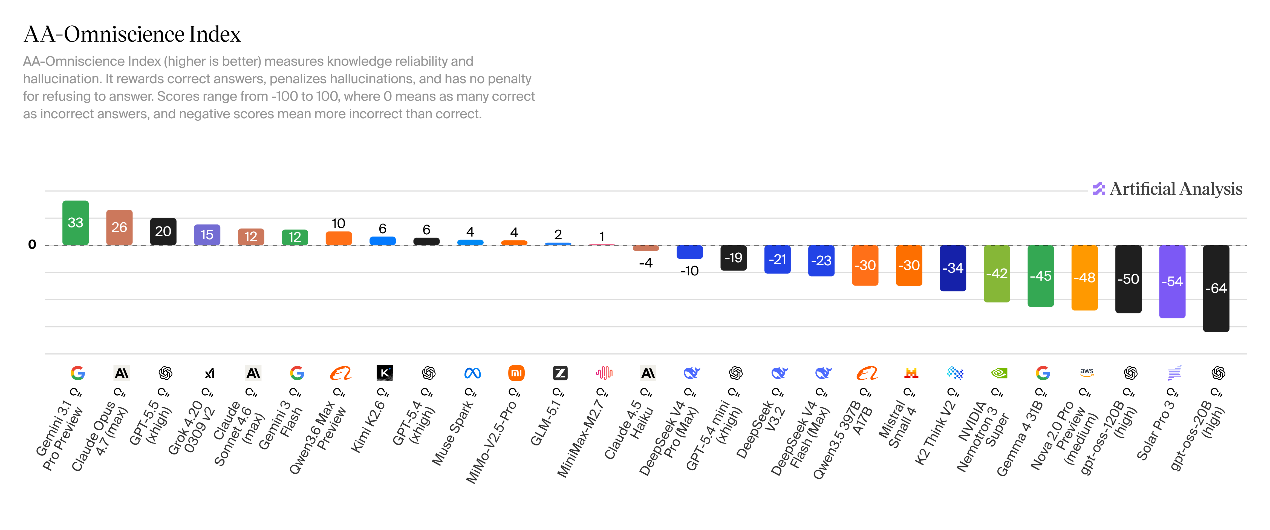
相较于V3.2的幻觉率(82%),V4两款模型的幻觉问题突出:V4-Pro幻觉率为94%、V4-Flash幻觉率为96%,意味着模型在未知问题场景下,几乎都会强行生成答案。
DeepSeek-V4的运行成本低于顶级闭源模型,高于主流开源模型,较前代大幅上涨。完成全套人工分析智能指数测评,V4-Pro的运行成本为1071美元,仅不到Claude Opus 4.7(4811 美元)的四分之一;但对比同类开源模型仍偏高,高于Kimi K2.6(948 美元)、GLM-5.1(544美元)、DeepSeek-V3.2(71美元)、gpt-oss-120B(67 美元)。DeepSeek-V4-Flash运行成本仅约113美元,成本优势显著。
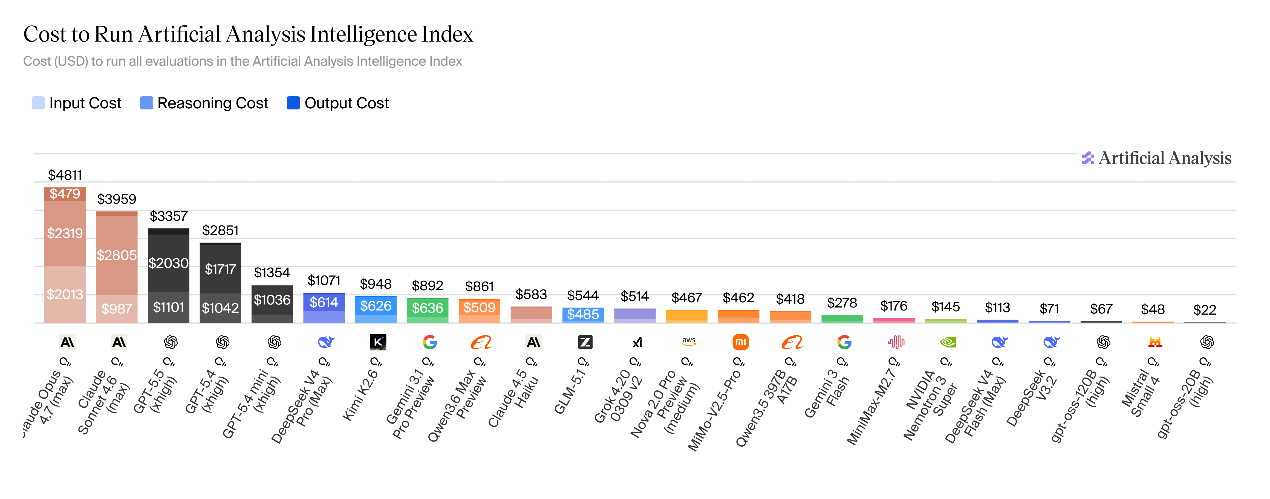
完成标准测评流程,V4-Pro输出Token消耗量达1.9亿,属于本次测评中Token消耗最高的模型之一;V4-Flash消耗进一步攀升至2.4亿Token。即便定价偏低,高额的Token消耗仍是V4-Pro综合使用成本高于其他开源模型的核心原因。
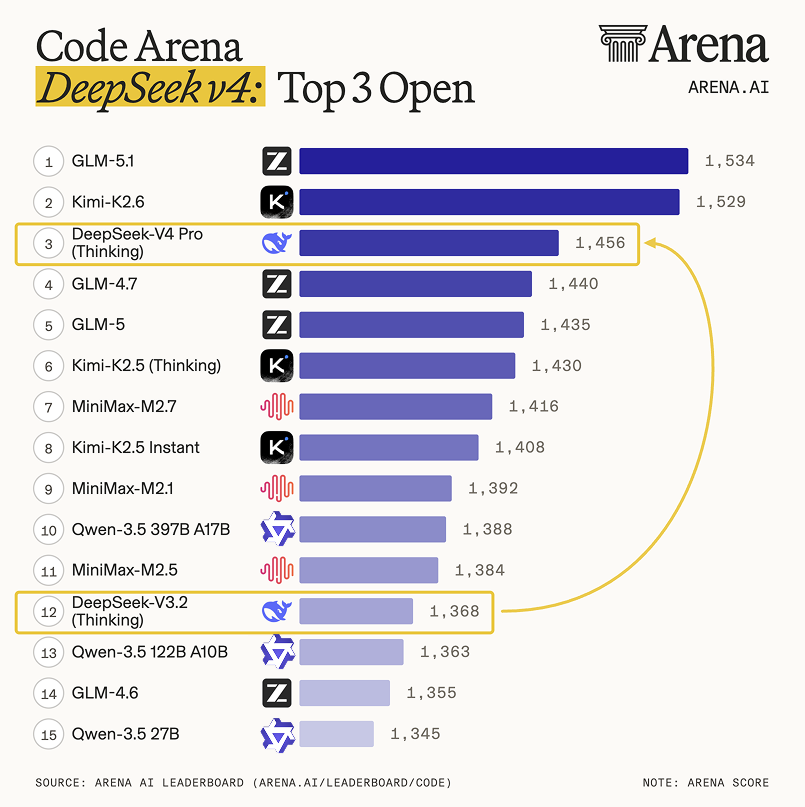
在其他评测中,大模型竞技场Arena.ai将DeepSeek-V4-Pro定性为“相较DeepSeek-V3.2的重大飞跃”,在其代码竞技场中位列开源模型第3位、综合第14位。DeepSeek-V4-Pro在智能体网页开发任务中与GPT-5.4-high和Gemini-3.1-Pro处于同一水平。在其文本竞技场中,DeepSeek-V4-Pro位列开源模型排名第2、综合第14,与Kimi-2.6持平。DeepSeek-V4-Flash位列开源模型排名第10、综合第14。
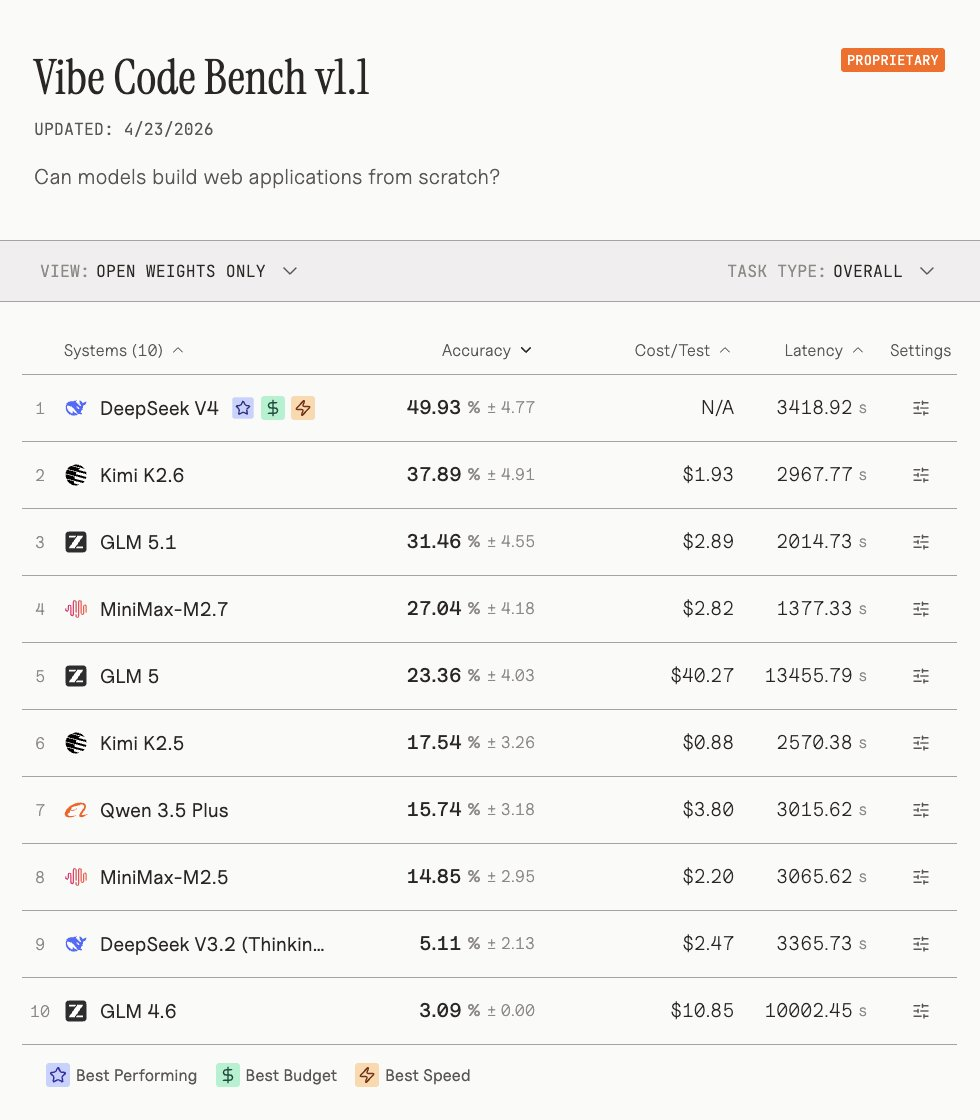
另一家测评方Vals AI称,DeepSeek-V4在其Vibe Code Benchmark(氛围代码基准)中以“压倒性优势”拿下开源权重模型榜首,较上代V3.2实现约10倍性能跃升,甚至击败了像Gemini 3.1 Pro这样的顶尖闭源模型。DeepSeek-V4也是唯一一个在Vibe Code Benchmar上突破40%的开源权重模型。
相较于DeepSeek-V4的能力,海外更加关注DeepSeek与华为的合作。
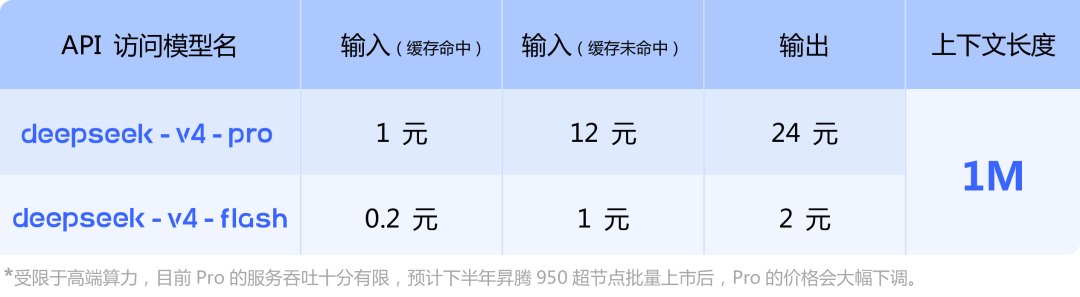
在DeepSeek-V4公布API价格信息的最下方,官方特别标注指出:“受限于高端算力,目前Pro的服务吞吐量十分有限,预计下半年昇腾(Ascend)950超节点批量上市后,Pro的价格会大幅下调。”
DeepSeek在技术报告中称,V4已在NVIDIA GPU和华为昇腾NPUs平台上验证了精细粒度的EP(专家并行)方案,相较于强大的非融合基线,其在通用推理任务上可实现1.50~1.73倍的加速效果,而在对时延敏感的场景(如RL推演和高速代理服务)中则可达到1.96倍的加速效果。
而在V4发布后,华为昇腾也同步宣布“超节点全系列产品支持DeepSeek-V4系列模型”。据悉,昇腾950通过融合kernel和多流并行技术降低Attention计算和访存开销,大幅提升推理性能,结合多种量化算法,实现了高吞吐、低时延的DeepSeek-V4模型推理部署。
对于DeepSeek此次与华为合作,市场研究机构Omdia半导体研究主管何辉表示:“这对中国人工智能行业而言意义重大。”
他进一步说道:“华为昇腾芯片是中国自研水平最高、可替代英伟达的产品。DeepSeek-V4大模型适配搭载华为芯片,标志着中国顶级大模型如今已能够实现国产化硬件落地运行。”
高盛分析师Christopher Moniz点评称,DeepSeek-V4预览版发布后,GPU及国产芯片板块应声走强。核心关注点之一是支撑V4模型的芯片底层架构:包括模型训练所使用的芯片,以及推理阶段搭载的硬件设备。华为搭载昇腾AI处理器的新一代人工智能计算集群,可适配运行DeepSeek-V4模型。这也意味着,中国自研AI硬件生态,正在为DeepSeek持续迭代前沿大模型提供算力支撑。
DeepSeek此次技术路线转向,也印证了英伟达首席执行官黄仁勋此前的担忧:英伟达正面临失去中国开发者生态的风险。
本月上旬,英伟达创始人黄仁勋在接受Dwarkesh Patel专访时曾言:“如果DeepSeek先在华为平台上发布,那对美国来说将是灾难性的。”在黄仁勋看来,虽然DeepSeek是一款开源模型,同样可被用于英伟达产品上,但如果DeepSeek专门针对华为算力进行优化,在高端算力采购受限等局限下,英伟达将处于劣势。
与DeepSeek-R1不同,DeepSeek-V4并没有引发美国科技股大跌。晨星高级股票分析师Ivan Su表示,DeepSeek-V4很难复刻推理模型R1当初的市场影响力,因为交易市场早已充分消化了预期:中国人工智能技术具备竞争力,且使用成本更低。
Ivan Su还称,DeepSeek此次全新的产品定位,将国内其他开源大模型直接划入竞品行列。
布鲁金斯学会研究员Kyle Chan表示,DeepSeek-V4令人印象深刻,因为它是一个接近最先进水平的模型,具有高效的100万Token上下文长度,并且可以在华为的新芯片上运行。DeepSeek-V4没有复制“DeepSeek-R1时刻”,因为外界对中国AI能力的期望值要比以往高得多。
免责声明:本文内容与数据仅供参考,不构成投资建议,使用前请核实。据此操作,风险自担。
封面图片来源:每经记者 兰素英摄



